Content
In Assignment 2, we will build a neural machine translation model using RNN and attention. Then we will do some analysis of NMT systems.
Model constructure
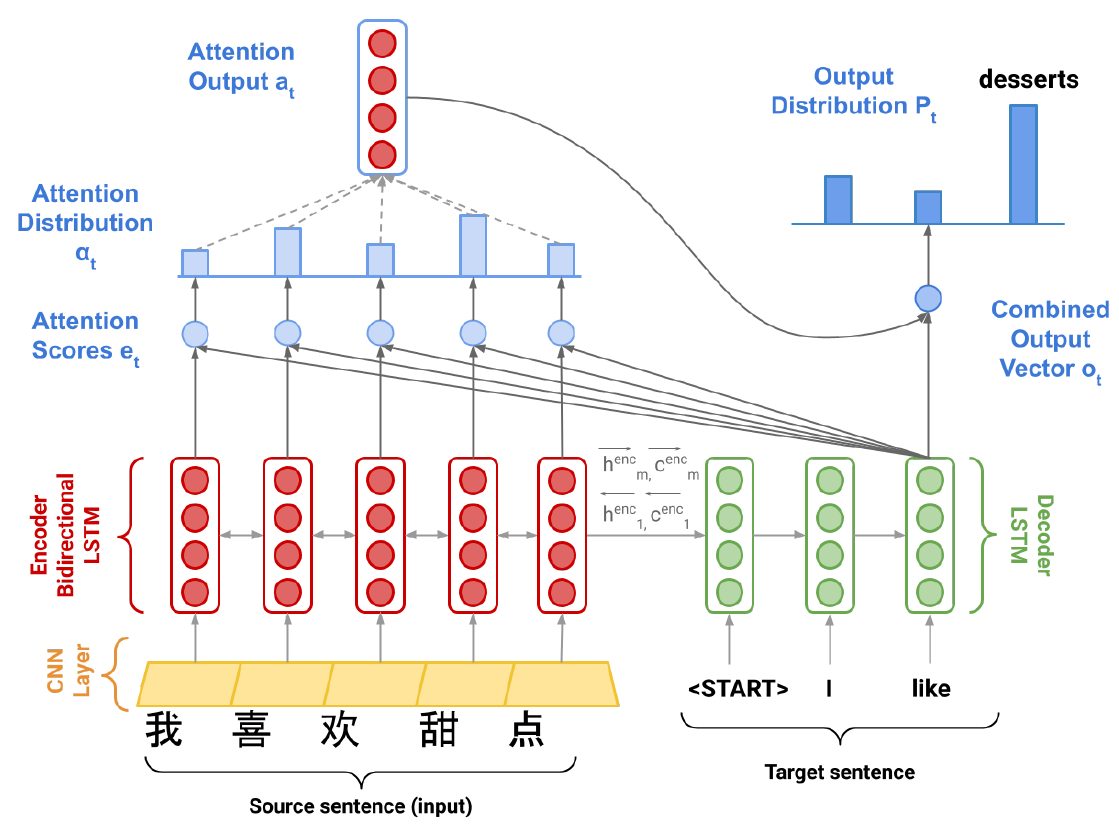
- Word embedding layer
- Source CNN layer: 1D in the dimension of sentence length, kernel size = 2
- Encoder: bidirectional LSTM
- Decoder: LSTM
- On the step, we look up the embedding of the target word and concatenate it with the combined output vector to produce the input to the decoder at step , which will be .
- Attention: multiplicative attention
- Combined output
- Output layer
Results
BLEU Score: 20.11
epoch: 5, patience: 1, others are default.
Attention score
How to choose?
- Dot product: simple and fast, but not good for capturing complexity.
- Multiplicative: good for long sentences, but kind of slower but efficient.
- Additive: good for complexity, but very slow and expensive.
Analysis of NMT
1D CNN
Adding a 1D Convolutional layer can help capture local patterns and relationships between adjacent characters in the input sequence. This is particularly useful in Mandarin Chinese, where characters can combine to form words or morphemes. The convolutional layer can learn to recognize these combinations and extract relevant features, which can then be passed to the bidirectional encoder for further processing.
Improvement
- More data exposure: let the model to learn more from the data
- More complex model: more layers, more heads for the model to capture more complex patterns
- Advanced mechanisms: advanced mechanisms such as transformer, self-attention, etc.
- Other training techniques: more epochs, adaptive learning rate, more dropout, etc.
BLEU
Suppose we have a reference sentence and a candidate sentence , and we want to calculate the BLEU score for given . Here we set n-gram size to be 4. And is the weight of the -gram precision.
the BLEU score is not a perfect metric for evaluating NMT translations. It is a good metric for comparing translations with different reference translations, but it does not take into account the fact that there may be multiple reference translations.
Advantages
- It is fast and cheap to compute, as it does not require human annotators.
- It is objective and reproducible, as it is based on a fixed set of reference translations.
Disadvantages
- Surface n-gram overlap only: poor at judging meaning/adequacy, paraphrases, and longrange reordering; weak at sentence-level.
- Precision-heavy with a simple brevity penalty: can be gamed and struggles with morphology/rarer words and semantic correctness.
Note
- In this assignment, we build the NMT model from scratch. I think it’s a good way to understand the whole image of the model structure with both the math and the code.
- I also see some limitations of NMT from this assignment. Like the BLEU score is not a perfect metric while it’s a good metric for comparing translations with different reference translations.