Info
- Acctually, there is not so much math that we need to do. However it’s gonna make it easier to understand if we understand how to calculate the basic things i.e. derivatives / gradients.
- The reason that modern nueral network is powerful is that it utilizes matrix caluculation with python(enven though python is not so efficient in some way). So here we do some matrix calculus.
Simple NN
--- config: layout: dagre look: handDrawn --- flowchart LR subgraph subGraph0["Input Layer"] direction LR x1(("x₁")) x2(("x₂")) x3(("x₃")) x4(("x₄")) x5(("x₅")) xb[("b")] end subgraph subGraph1["Hidden Layer"] direction LR h1(("h₁")) h2(("h₂")) h3(("h₃")) end subGraph0 --> subGraph1 subGraph1 --> s(("s")) style subGraph0 fill:#C8E6C9 style subGraph1 fill:#E1BEE7 style s fill:#BBDEFB
- input layer ⇒ hidden layer ⇒ output layer
- is the activation function, which is usually ReLU or sigmoid.
Note
- So for this simple neural network, we can use the above formula to calculate the output . The input layer is the input vector , the hidden layer is the hidden vector , and the output layer is the output scalar .
- And thoughout the network, we need to calculate the gradient of the loss function with respect to each parameter, which is . For simplicity, we can just use to represent the gradient of the loss function with respect to each parameter.
Tools
- Jacobian Matrix
- Chain Rule
Calculation
Going back to Simple NN and using Tools, we have:
- What is ? Because is element-wise, which means
- Other Jacobians
For example:
- What is ?
- What is ?
Shape of derivatives
- Jacobian Form: the result should be a row vector. For easy calculation of chain rule.
- Shape Convention: the result should be a column vector. For easy SGD when training.
- Use Jacobian form as much as possible, reshape to follow the shape convention at the end.
- Always follow the shape convention.
Backpropagation
Backpropagation is almost the most important part of DL. There are two steps:
- Using upstream derivatives and local derivatives to calculate downstream derivatives.
- Re-using these derivatives to update the parameters.
- Calculate all gradients at once just like using
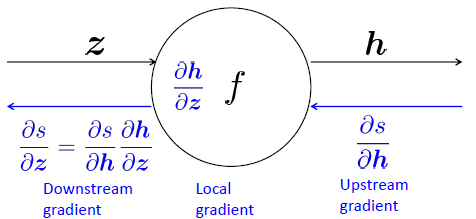
How to calculate the gradients in NN frame?
- Forwardprogate and record the intermediate values
- Backpropagate and calculate the gradients
- Load basic explicit formula for each step’s gradient
- Calculate the upsteam gradient
- Then calculate the local gradient
- Calculate the downsteam gradient